Python爬虫 - 简单抓取百度指数
前言
有点忙,没空写东西,这是之前写的,加了些配图而已
这次要爬的网站是百度指数
正文
一、分析
打开网站百度指数,呈现出来是这样的
如果搜索的话就需要登陆了,如果没有什么特别频繁的请求的话,直接登陆复制Cookie就完事了
这里以 酷安 为例搜索
这一栏是选择时间范围的,拖拽它能将范围选择更广
我将其拖拽至2011,调试窗口可以看到请求,是个GET请求,参数有四个,除了 area 其他的都很好理解
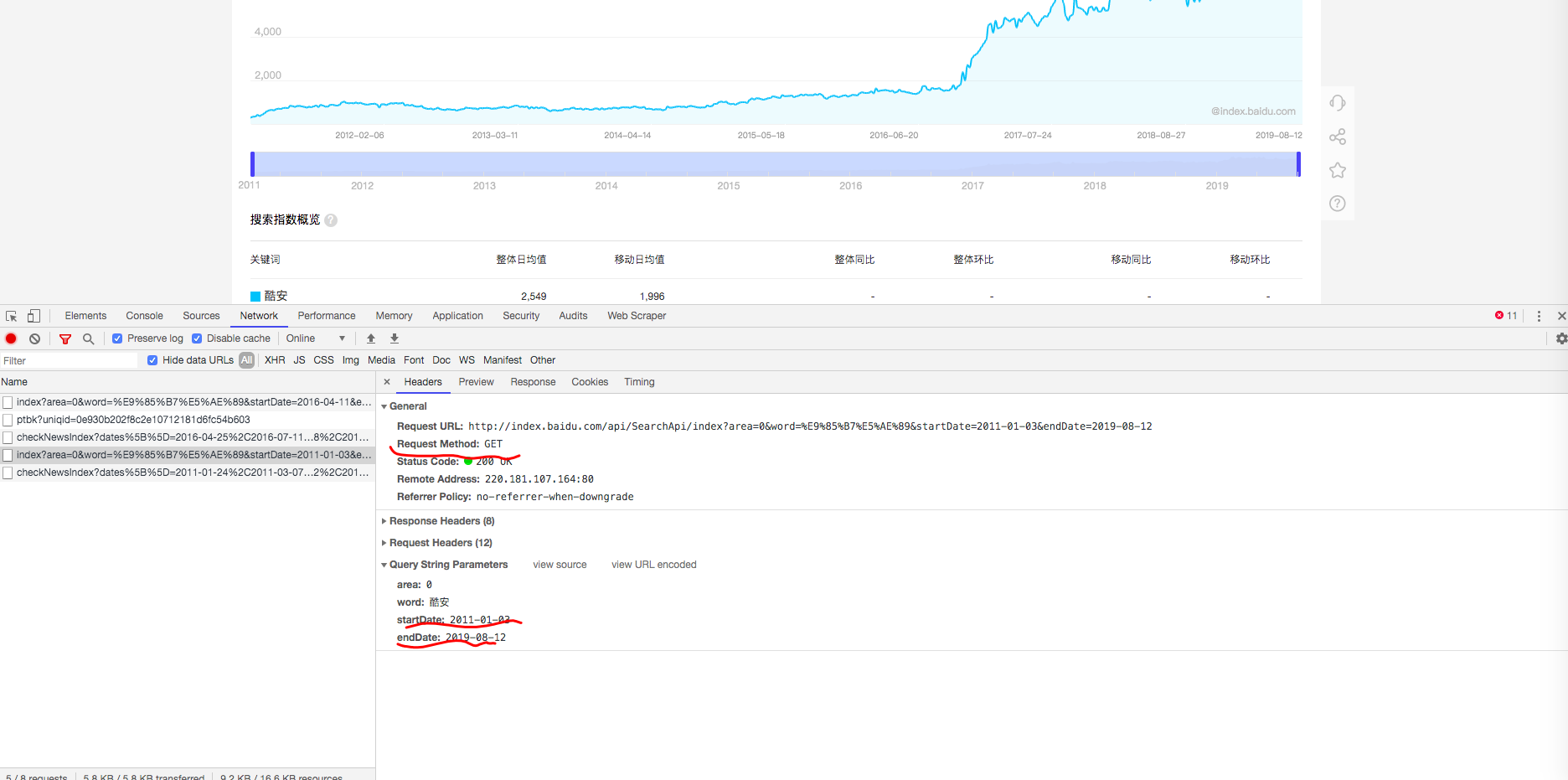
切换到 Preview 预览窗口,通过分析,个人认为比较可疑的几个Key有这些:uniqid、all、pc、wise、data
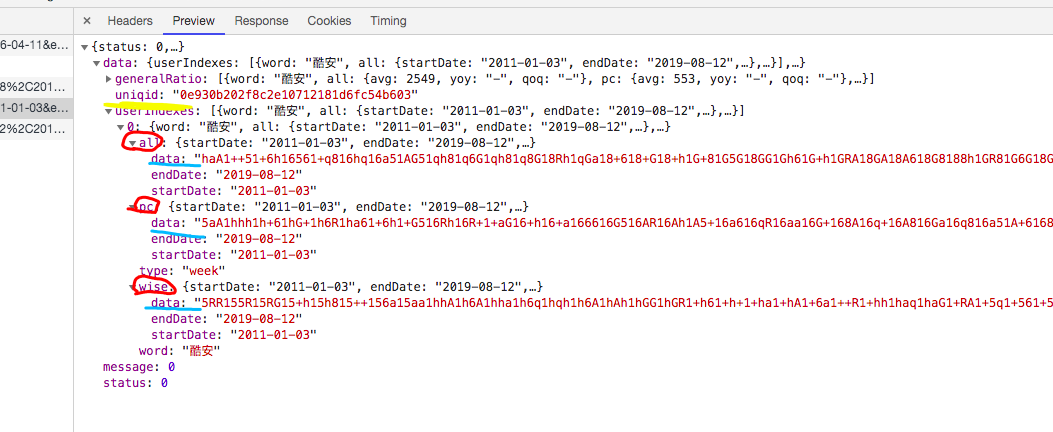
其中data可以看到应该是加密了的,all是表示全部数据,pc是指pc端,wise是移动端,这些可以在js文件里找到;首先先搞清楚这个像加密了的data是怎么解密的;我们现在知道这个数据是json格式,那么它处理肯定要从中取出这些data,所以,重新刷新一下网页,目的是为了让所有js都能加载出来,然后利用搜索功能从中找。搜索过程就不上图了,我是搜索 decrypt找到的;首先,我用decrypt找到了一个js文件,其中有一个名为decrypt的方法

这个js文件中有很多decrypt的搜索结果,在不知道多少行处找到了一个名为 fetchThrendIndexLive 的方法,这个方法用我工地英语翻译为获取趋势指数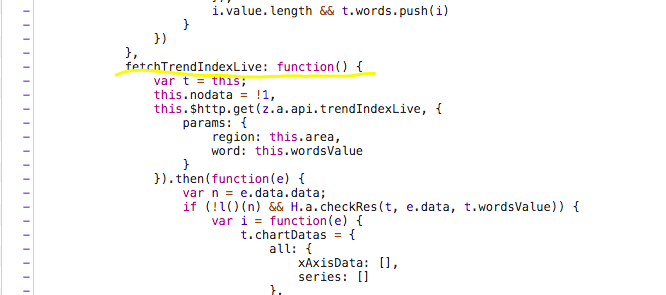
这里调用了名为decrypt的方法,是不是上面那个我不知道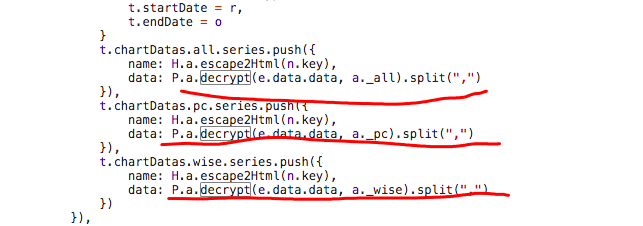
这次我不打算用charles的替换js文件功能了,直接用浏览器的调试功能+console就行了
右键js的请求,Open in Sources panel
直接在这里下断点,然后刷新页面
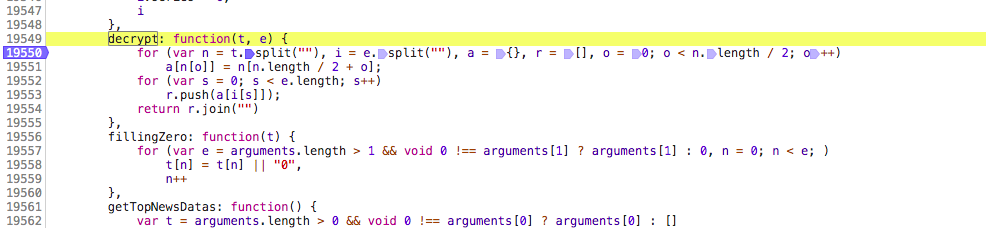
在这停顿后可以看到两个参数的内容
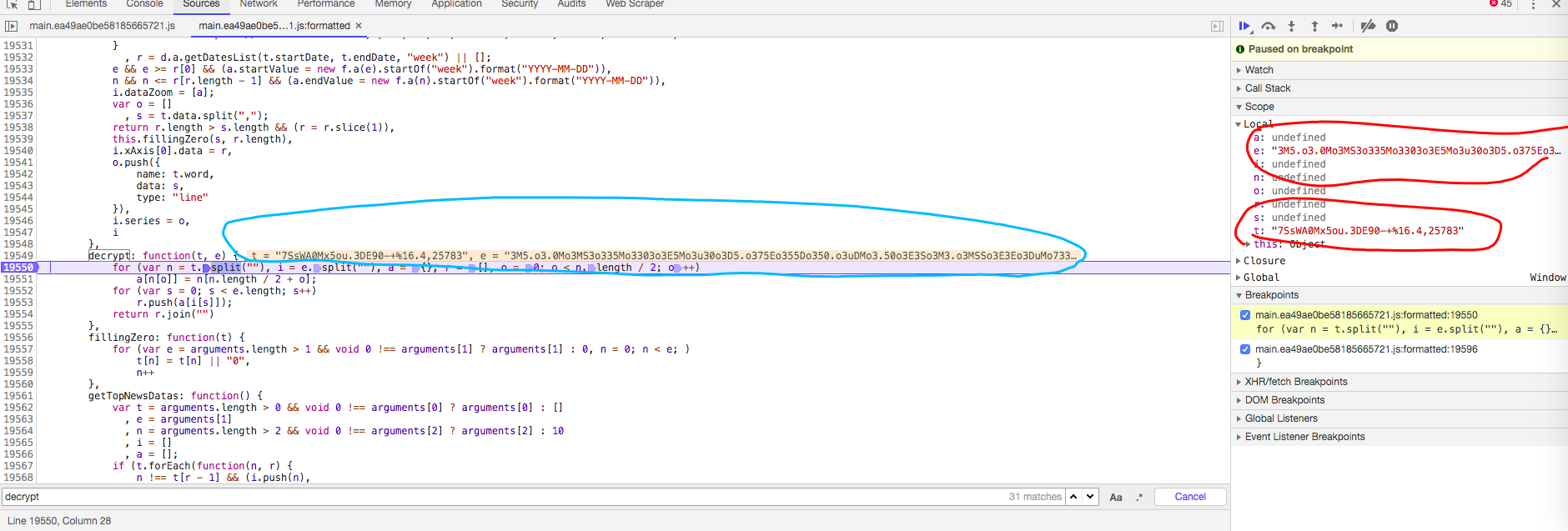
想要知道这两个参数是什么很简单,回到Network看请求里的json;其中e参数是data,t参数不太清楚是什么。
for循环里第一步是先将t字符串按单个字符分割,返回的列表保存在n变量里;
然后将e也按单字符分割,保存到i变量里
a是一个字典,r是一个列表
从右边的 Scope 中可以看到
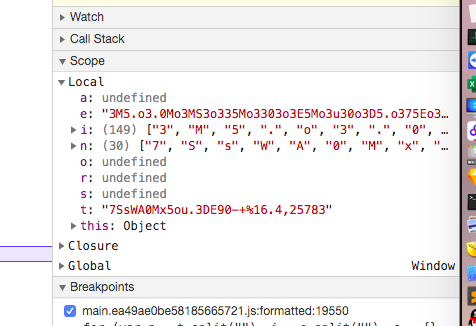
以t的字符长度遍历,a中key为t遍历的字符,a中value为:从t中按索引取的值,其中索引为:t的字符长度除2后加上当前遍历的索引(a[n[o] = n[n.length/2 + o])
这里始终没有用到i,也就是我们能获取到的data,这个i在第二个循环中才被用到;
第二个循环是遍历e,结果保存在r列表里,这里的遍历很容易就看得懂。。我就不分析了,自己都头晕,直接用python抄一遍就行了;
最后是将r列表里的内容合并为一个字符串然后返回;
二、整理思路
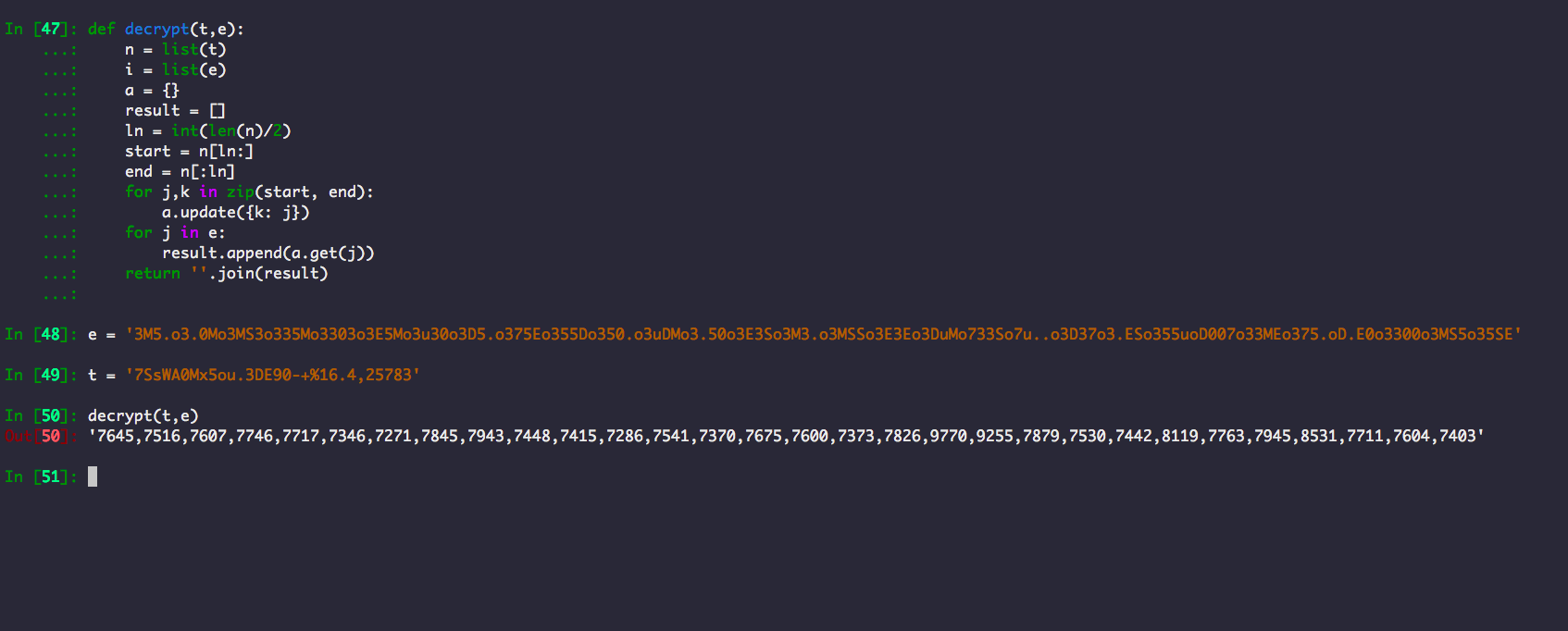
解密方法对应python代码为:
1 | def decrypt(t,e): |
完全照搬。。可能有写地方可以简化,但我懒得去处理了,最后返回的是这个玩意儿
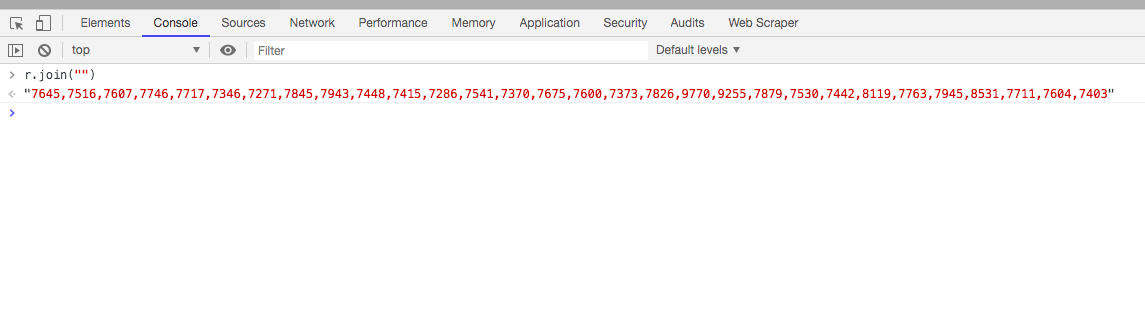
python运行结果
到这可能都觉得已经解决了,可你不知道t这个参数是什么,怎么来的,这里我就不带各位分析了,你么可以自己尝试分析分析,我直接说结果,之前我就指出了几个可疑的东西,其中uniqid在获取t参数需要用到,这个t其实是叫ptbk,获取这个ptbk的url:http://index.baidu.com/Interface/ptbk?uniqid= 有一个参数uniqid,GET请求,返回json内容
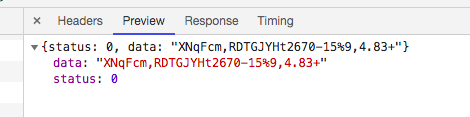
获取uniqid和data的url:http://index.baidu.com/api/SearchApi/thumbnail?area=0&word= (如果要指定日期只需要在word后面追加&startDate=、&endDate=就行)
所以可以明确一下思路:
1、通过url获取uniqid和data
2、通过uniqid获取ptbk
3、通过ptbk和data解密
解密后的东西就是我们要的
三、代码部分
完整代码:
1 | import requests |
输出
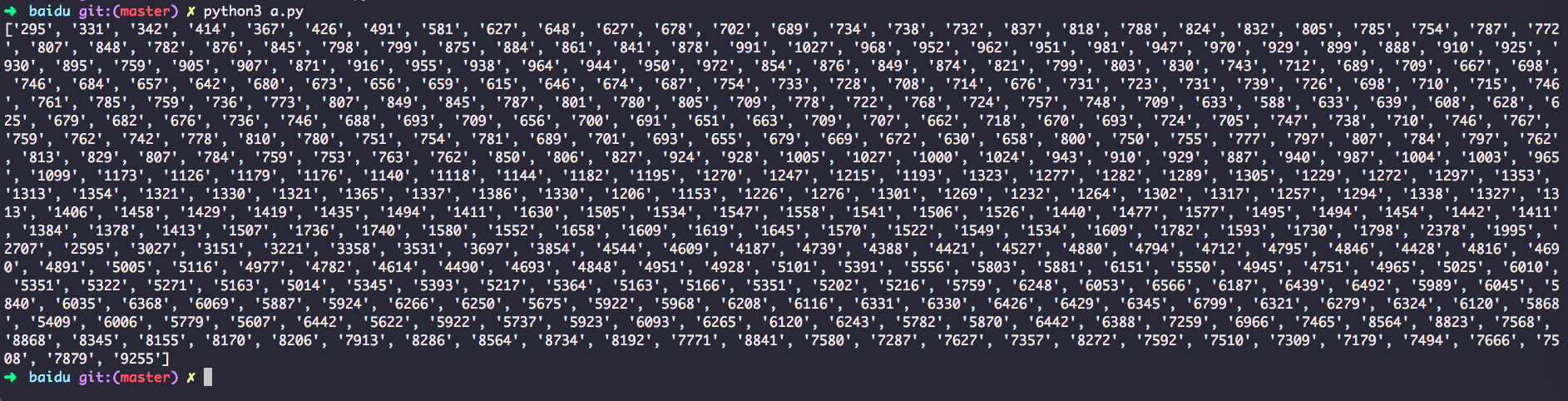
END
转载请注明出处